Elasticsearch入门
一、简介
1、简介
Elasticsearch是一个实时的分布式开源搜索和分析引擎,可以实时对数据进行搜索、分析和可视化。它可以用于许多目的,但是它更擅长的一个场景是索引半结构化数据流(例如日志)或解码网络数据包。
Elasticsearch在集群环境中运行,集群可以是一个或多个服务器,集群中的每个服务器都是一个节点。与所有文档数据库一样,记录(records)称为文档(documents)。文档存储在索引中,索引可以分片,也可以拆分成更小的部分。Elasticsearch可以在单独的节点上运行这些分片,以便跨服务器分配负载。
Elasticsearch使用Apache Lucene对文档进行索引,以便快速搜索。它提供了处理各种用例(use cases)数据的速度和灵活性:
-
向应用程序或网站添加搜索框
-
存储和分析日志、指标、安全事件数据
-
用机器学习来自动建立实时数据行为模型
-
使用Elasticsearch作为存储引擎自动化业务工作流
-
使用Elasticsearch作为地理信息系统(GIS)来管理、集成和分析空间信息
-
使用Elasticsearch作为生物信息学研究工具存储和处理遗传数据
2、文件和索引
Data in: documents and indices
Elasticsearch是一个分布式文档存储,它不是将信息存储为列式数据行,而是存储已经序列化为JSON文档的复杂数据结构。当集群中有多个Elasticsearch节点时,存储的文档分布在集群中,可以从任何节点访问。
当一个文档被存储时,它会被编入索引,并且几乎可以在1秒内完全搜索到。Elasticsearch使用一种称为倒排索引的数据结构,支持非常快速的全文搜索。倒排索引会列出出现在任何文档中的每个唯一单词,并标识出每个单词出现在的所有文档。
索引可以看作是文档的优化集合,每个文档(document)是字段(field)的集合,字段是包含数据的键值对。默认情况下,Elasticsearch索引每个字段中的所有数据,并且每个索引字段都有一个专门的、优化的数据结构。例如,文本字段存储在倒排索引中,数字和地理字段存储在BKD树中。
Elasticsearch还可以对文档进行索引而无需明确指定如何处理文档中可能出现的每个不同字段。当启用动态映射时,Elasticsearch将自动检测并向索引添加新字段。用户可以定义规则来控制动态映射(mapping),并显式定义映射来完全控制字段的存储和索引方式。
为了不同的目的,以不同的方式对同一个字段进行索引通常是有用的。例如,可能希望将字符串字段索引为用于全文搜索的文本字段和用于排序或聚合数据的关键字字段。也可以选择使用多个语言分析器来处理包含用户输入的字符串字段的内容。
3、搜索和分析
Information out: search and analyze
- 搜索数据
Elasticsearch为管理集群、索引和搜索数据提供了一个简单、一致的REST API。Elasticsearch REST API支持结构化查询、全文查询和两者结合的复杂查询。结构化查询类似于SQL中可以构造的查询类型。例如:可以在员工索引中搜索性别和年龄字段,并根据hire_date字段对匹配项进行排序。全文查询找到所有匹配查询字符串的文档,并按相关性排序返回这些文档。除了搜索单个词汇外还可以执行短语搜索、相似性搜索和前缀搜索,并获得自动完成的建议。
可以使用Elasticsearch的JSON风格查询语言访问所有搜索功能,也可以构造SQL风格的查询来在Elasticsearch内部搜索和聚合数据;JDBC和ODBC驱动程序允许广泛的第三方应用程序通过SQL与Elasticsearch交互。
- 分析数据
Elasticsearch聚合(aggregations)能够构建数据的复杂摘要,并深入了解关键指标、模式和趋势。
由于聚合使用了用于搜索的相同的数据结构,所以它们也非常快,可以实时分析和可视化数据;报告和仪表盘也会随着数据的更改而更新,以便根据最新信息采取行动。
聚合也可以和搜索请求一起运行:可以在单个请求中同时搜索文档、筛选结果和执行分析。
如果想要自动分析时间序列数据(time series data),可以使用机器学习特性在数据中创建正常行为的准确基线,并识别异常模式。
4、集群、节点和分片
Scalability and resilience: clusters, nodes, and shards
Elasticsearch是高可用的,并且可以按需扩展:可以向集群添加服务器(节点)以增加容量,Elasticsearch会自动将数据和查询负载分布到所有可用节点。
Elasticsearch索引只是一个或多个物理分片的逻辑分组,其中每个分片实际上是一个自包含的索引。通过将文档分布在多个分片的索引中,并将这些分片分布在多个节点上,Elasticsearch可以确保冗余性,这既可以防止硬件故障又可以在节点添加到集群时增加查询能力。当集群增长(或缩小)时,Elasticsearch会自动迁移碎片以平衡集群。
有两种类型的分片: 主分片和副分片。索引中的每个文档都属于一个主分片,副分片是主分片的副本;副本提供数据的冗余副本,以防止硬件故障,并增加处理像搜索或检索文档这样的读请求的能力。
在创建索引时,索引中主分片的数量是固定的,但是可以随时更改副本的数量,而不会中断索引或查询操作。
在分片大小和为索引配置的主分片数量方面,有许多性能考虑和权衡。分片越多,维护这些的开销就越大,当Elasticsearch需要重新平衡集群时,分片尺寸越大,移动分片所需的时间就越长。
出于性能原因,集群中的节点需要在同一个网络上。在不同数据中心的节点之间平衡集群中的分片将花费的很长时间。但高可用性体系要求避免将所有机器部署到同一位置,当一个位置发生事故停机时,另一个位置的服务器需要能够接管。因此,可以使用跨群集复制(Cross-Cluster Replication)。
CCR提供了一种自动从主集群同步索引到辅助远程集群的方法,辅助远程集群可以作为热备份。如果主集群失败,辅助集群可以接管。也可以使用CCR创建辅助集群,以满足用户在地理位置上接近的读请求。
跨集群复制是主动-被动(active-passive)复制,主集群上的索引是活动的领导者(active leader)索引,并处理所有写请求,复制到次要集群的索引是只读随从(followers)。
5、基础概念
- 索引
索引是含有相同属性的文档集合。
- 类型
索引可以定义一个或多个类型,文档必须属于一个类型。
- 文档
文档是可以被索引的基本数据单位。
- REST API
<PROTOCOL>://<HOST>:<PORT>/<索引>/<类型>/<文档ID>
二、安装与运行
备注:此处以windows为例。
- 下载
下载Elasticsearch并解压即可。
- 运行
解压后在命令行切换到bin目录,运行:
elasticsearch.bat
之后访问http://127.0.0.1:9200/检测是否成功,正常会返回类似以下内容:
{
"name" : "ACER",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "FANu5b-sRySxYOLv30SL-g",
"version" : {
"number" : "7.10.1",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "1c34507e66d7db1211f66f3513706fdf548736aa",
"build_date" : "2020-12-05T01:00:33.671820Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
此时有一个单节点 Elasticsearch 集群启动和运行。
- 多节点
运行以下命令,启动另外两个节点:
elasticsearch.bat -E path.data=data2 -E path.logs=log2
elasticsearch.bat -E path.data=data3 -E path.logs=log3
使用cat API查看集群状态:
curl -X GET "localhost:9200/_cat/health?v=true&pretty"
响应类似如下内容:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1610888712 13:05:12 elasticsearch green 3 3 6 3 0 0 0 0 - 100.0%
- 使用crul命令与Elasticsearch交互
curl HTTP格式如下:
curl -X <VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
三、基本用法
1、索引(Index)
- 索引
集群启动并运行之后,就可以对一些数据进行索引了。可以使用一个简单的PUT请求完成这一操作,该请求指定要添加文档的索引、唯一的文档ID以及请求主体中的一个或多个字段–值("field": "value")对:
PUT /customer/_doc/1
{
"name": "John Doe"
}
执行curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H "Content-Type:application/json" -d "{\"name\":\"Jack\"}":
Windows需注意参数需要用双引号。
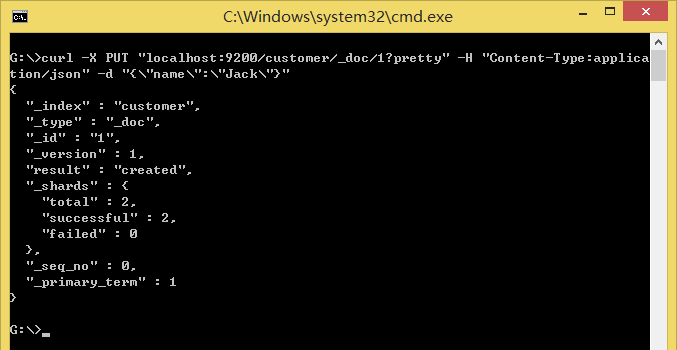
如果customer索引不存在,则自动创建该索引,添加一个ID为1的新文档,存储name字段并为其建立索引。
- 查询
新文档(new document)可以立即从集群中的任何节点查询到,可以通过一个指定文档ID的GET请求来查询:
GET /customer/_doc/1
执行curl -X GET "localhost:9200/customer/_doc/1?pretty":
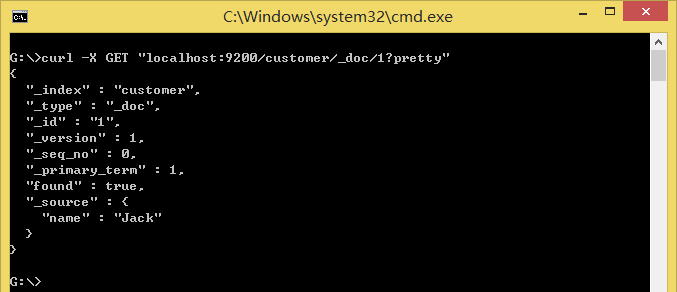
响应表示找到了指定ID的文档,并显示了被索引的原始源字段。
- 批量索引
如果要索引大量文档,可以使用bulk API批量提交。批量处理操作要比单独提交请求快得多,因为这样可以最大限度地减少网络消耗。
todos.json文件中有5个待办(表示批量数据):
{"index":{"_id":"1"}}
{"userId":1,"id":1,"title":"Read a Book","completed":false}
{"index":{"_id":"2"}}
{"userId":1,"id":2,"title":"Run 5000 meters","completed":true}
{"index":{"_id":"3"}}
{"userId":2,"id":3,"title":"Dinner with friends","completed":true}
{"index":{"_id":"4"}}
{"userId":3,"id":4,"title":"Play golf","completed":false}
{"index":{"_id":"5"}}
{"userId":3,"id":5,"title":"Dating a girlfriend","completed":false}
使用_bulk请求将待办(TODO)数据索引到todo索引中:
curl -H "Content-Type: application/json" -X POST "localhost:9200/todo/_bulk?pretty&refresh" --data-binary "@todos.json"
查询状态:
curl "localhost:9200/_cat/indices?v=true"

2、搜索(Search)
-
普通查询
可以通过
_search请求来搜索,需要在请求URI中指定要搜索的索引名称;例如,获取按id排序的todo索引的所有文档:curl -X GET "localhost:9200/todo/_search?pretty" -H "Content-Type: application/json" -d "{\"query\":{\"match_all\":{}},\"sort\":[{\"id\":\"asc\"}]}"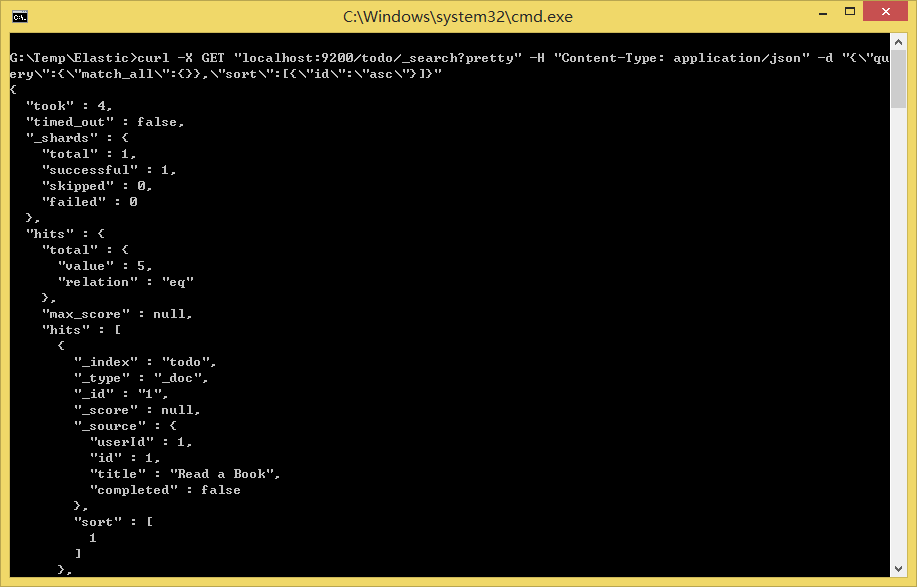
响应中除了数据外还提供了以下信息:
-
took:Elasticsearch运行查询需要的时间(毫秒)
-
timed_out:查询请求是否超时
-
_shards:搜索了多少分片,并分别列出成功、失败或跳过的碎片数量
-
max_score:找到的最相关的文档的分数
-
hits.total.value:找到匹配文档的个数
-
-
分页查询
Elasticsearch不维护跨请求的任何状态信息,如果需要分页查询,可以在请求中指定from和size:
curl -X GET "localhost:9200/todo/_search?pretty" -H "Content-Type: application/json" -d "{\"query\":{\"match_all\":{}},\"sort\":[{\"id\":\"asc\"}],\"from\":3,\"size\":3}" -
条件(匹配)查询
可以通这query的
match参数指定查询条件,例如,查找title中包含friends或girlfriend的待办:curl -X GET "localhost:9200/todo/_search?pretty" -H "Content-Type: application/json" -d "{\"query\":{\"match\":{\"title\":\"friends girlfriend\"}}}"结果返回2个满足条件的文档。
使用
match_phrase表示执行短语搜索而不是匹配单个词汇,例如,查找title中包含many friends的待办:curl -X GET "localhost:9200/todo/_search?pretty" -H "Content-Type: application/json" -d "{\"query\":{\"match_phrase\":{\"title\":\"many friends\"}}}"结果返回0个满足条件的文档。
-
复杂查询
如果要构造更复杂的查询,可以使用
bool查询来组合多个查询条件:条件中使用must表示必须,使用should表示可选(或),使用must_not表示必须不。例如,查找userId不是3的未完成的待办:{ "query": { "bool": { "must_not": [{ "match": { "userId": 3 } }], "must": [{ "match": { "completed": false } }] } } }curl -X GET "localhost:9200/todo/_search?pretty" -H "Content-Type: application/json" -d "{\"query\":{\"bool\":{\"must_not\":[{\"match\":{\"userId\":3}}],\"must\":[{\"match\":{\"completed\":false}}]}}}"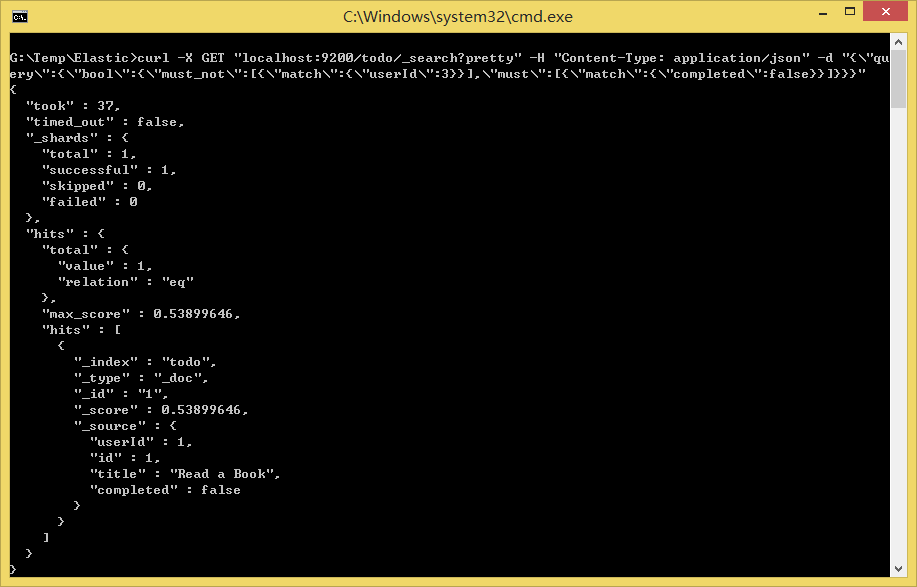
布尔查询中的
must、should和must_not都称为查询子句,文档满足每个must或should条件的程度决定了文档的相关性得分,得分越高,文档就越符合搜索条件。默认情况下,Elasticsearch返回按照相关性得分排序的文档。must_not子句中的条件被视为筛选器,它影响文档是否包含在结果中,但不影响文档的评分。 -
使用范围过滤
例如,查询userId大于1,小于等于3的已完成或未完成的待办:
{ "query": { "bool": { "should": [ {"match": {"completed": false}}, {"match": {"completed": true}} ], "filter": { "range": { "userId": { "gt": 1, "lte": 3 } } } } } }curl -X GET "localhost:9200/todo/_search?pretty" -H "Content-Type: application/json" -d "{\"query\":{\"bool\":{\"should\":[{\"match\":{\"completed\":false}},{\"match\":{\"completed\":true}}],\"filter\":{\"range\":{\"userId\":{\"gt\":1,\"lte\":3}}}}}}"结果返回待办ID为:3、4、5的三条数据,即:
Dinner with friends、Play golf、Dating a girlfriend。
3、聚合
Elasticsearch聚合(aggregations)可以用来分析搜索结果。可以在一个请求中搜索文档、筛选,并使用聚合来分析所有结果。例如:按用户(userId)分组,统计未完成待办的个数,按降序排列:
{
"size": 0,
"query": {
"bool": {
"must": [
{"match": {"completed": false}}
]
}
},
"aggs": {
"group_by_userId": {
"terms": {
"field": "userId"
}
}
}
}
其中,"size":0表示响应中只包含聚合结果。
执行:
curl -X GET "localhost:9200/todo/_search?pretty" -H "Content-Type: application/json" -d "{\"size\":0,\"query\":{\"bool\":{\"must\":[{\"match\":{\"completed\":false}}]}},\"aggs\":{\"group_by_userId\":{\"terms\":{\"field\":\"userId\"}}}}"
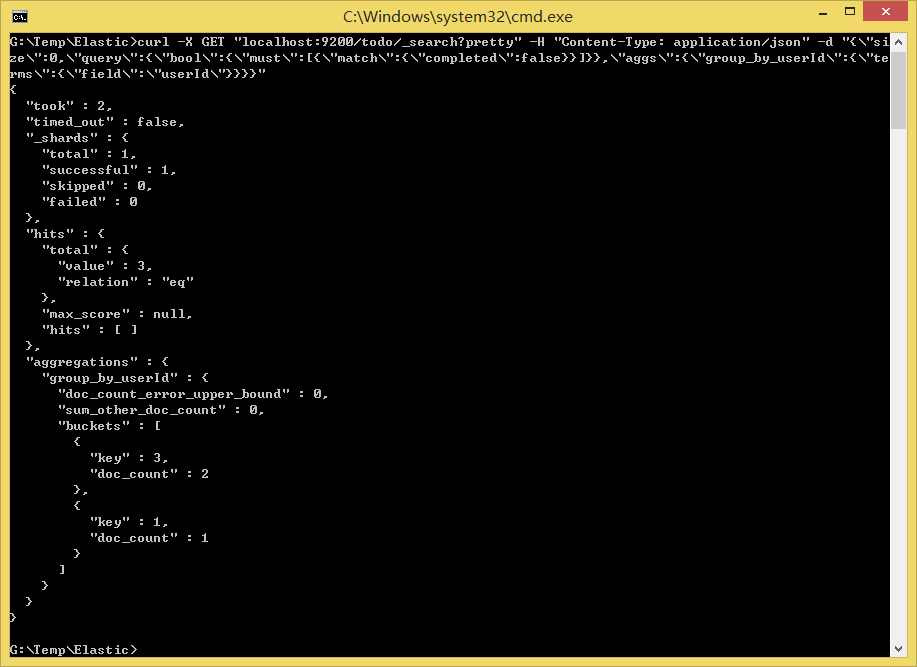
响应中buckets是userId的值以及对应的符合条件的文档的个数。
四、配置
Elasticsearch具有良好的默认值,并且只需要很少的配置;大多数配置可以在运行的集群上通过集群更新设置API( cluster update settings API)来更改。
Elasticsearch的配置文件位于安装目录的config文件夹下,有三个配置文件:
-
elasticsearch.yml:配置Elasticsearch
-
jvm.options:配置Elasticsearch JVM设置
-
log4j2.properties:配置Elasticsearch日志记录
1、Elasticsearch配置
配置格式是YAML;例如,更改数据和日志目录的路径配置:
path:
data: /var/lib/elasticsearch
logs: /var/log/elasticsearch
也可以使用展平(flattened)方式:
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
数组配置:
discovery.seed_hosts:
- 192.168.1.10:9300
- 192.168.1.11
- seeds.mydomain.com
或
discovery.seed_hosts: ["192.168.1.10:9300", "192.168.1.11", "seeds.mydomain.com"]
集群和节点设置可以根据它们的配置方式进行分类:
- Dynamic
可以使用群集更新设置API配置和更新正在运行的群集上的动态设置。还可以使用elasticsearch.yml在未启动或关闭节点上本地配置动态设置。
- Static
静态设置只能在未启动或关闭节点上使用elasticsearch.yml进行配置。
2、JVM配置
一般很少修改JVM配置,通常是为了更改堆大小等参数的配置。可以使用jvm.options文件或者esjavaopts环境变量来设置,优先使用前一种方式。
jvm.options文件包含一个以行分隔的JVM参数列表,该列表遵循一种特殊的语法:
- 以
#开头的行被视为注释并被忽略
# this is a comment
- 以
-开头的行设置应用于独立于JVM版本的JVM选项
-Xmx2g
- 以数字开头且后跟
:-的行表示只有在JVM版本与此数字匹配时才应用的JVM选项
8:-Xmx2g
- 以数字开头且后跟
-:-的行表示只有在JVM版本大于或等于此数字时才应用的JVM选项
8-:-Xmx2g
- 设置在两个JVM版本范围内应用的配置
8-9:-Xmx2g
五、REST API
Elasticsearch提供了一些REST API,可以直接调用这些API来配置和访问Elasticsearch特性。
1、语法
- 多目标语法(Multi-target)
在多目标语法中,可以使用逗号分隔的列表对多个资源运行请求:
POST /index1,index2,index3/_search
日期数字索引名称解析可以搜索某一范围时间内的索引,通过限制搜索索引的数量可以减少集群上的负载并提高执行性能。例如:在日志中搜索错误时,可以使用日期数字名称模板将搜索限制在过去两天内。
日期数字索引格式如下:
<static_name{date_math_expr{date_format|time_zone}}>
格式中的每段分别表示:静态名称、动态计算日期数字的表达式、日期格式(默认为yyyy.MM.dd)和可选的时区(默认为utc)。
Elasticsearch使用Quartz作业调度(Job Scheduler)程序中的cron解析器;cron表达式是以下形式的字符串:
<seconds> <minutes> <hours> <day_of_month> <month> <day_of_week> [year]
-
- Pretty Results
在请求后拼接
?pretty=true可以将返回的JSON格式化- Human Readable Output
此选项(human)可以将统计响应更改为人类可读形式,例如:
distance_meter = 20000当此配置为true时(?human=true)显示为distance_kilometer = 20KM- Response Filtering
使用
filter_path参数可以减少Elasticsearch返回的响应内容;参数中采用逗号分隔过滤列表:GET /_search?q=kimchy&filter_path=took,hits.hits._id,hits.hits._score对应的响应:
{ "took" : 3, "hits" : { "hits" : [ { "_id" : "0", "_score" : 1.6375021 } ] } } -
通配符(Wildcards)
通配符包括*、+、-,*匹配零个或多个,+匹配一个或多个,-表示排除。
POST /school*/_search
POST /school*,-schools_gov /_search
2、CAT API
通常来自Elasticsearch各种API的结果都以JSON格式显示,但对于人来说JSON并不总是那么容易阅读,因此Elasticsearch提供了CAT(compact and aligned text)APT的功能来帮助人们更容易阅读和理解结果来显示输出格式。Cat API中使用了各种各样的参数,这些参数分别用于不同的用途,例如,-V参数可以输出详细信息。
使用_cat命令可以列出所有可用的命令:
http://localhost:9200/_cat
或
curl -X GET "localhost:9200/_cat"
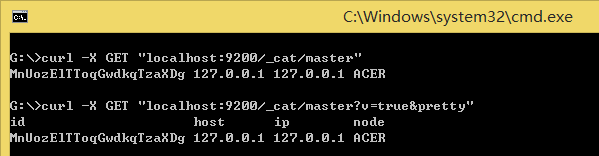
- Verbose
参数v用来显示详细输出:
curl -X GET "localhost:9200/_cat/master?v=true&pretty"
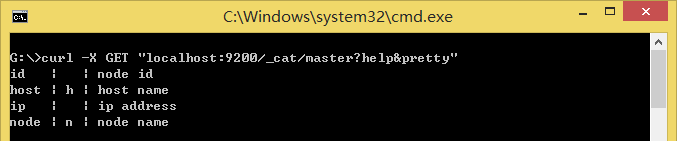
- Help
参数help可以输出可用的列:
curl -X GET "localhost:9200/_cat/master?help&pretty"
- Headers
参数h指定显示哪些列:
curl -X GET "localhost:9200/_cat/nodes?h=ip,port,heapPercent,name&pretty"

- Sort
使用参数s可以对指定的列进行排序,列由列名称或别名指定,多个列以逗号分隔;默认情况下是按升序排序,可以通过:asc或:desc指定排序方式。
curl -X GET "localhost:9200/_cat/templates?v=true&s=order:desc,index_patterns&pretty"
3、Cluster API
集群API用于获取有关集群及其节点的信息并对其进行更改。
- Cluster State
GET /_cluster/state/<metrics>/<target>返回有关群集状态的元数据,包括版本、主节点、其他节点、路由表等信息。
curl -X GET "localhost:9200/_cluster/state"
- Cluster Health
GET /_cluster/health/<target>返回集群的健康状态:
curl -X GET "localhost:9200/_cluster/health?pretty"
响应如下:
{
"cluster_name" : "elasticsearch",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 10,
"active_shards" : 20,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
六、索引模块
1、简介
Elasticsearch由许多模块组成,其中索引模块是根据索引创建的模块,它控制与索引相关的所有方面。
索引是将数据添加到Elasticsearch的过程,将数据提供给Elasticsearch时,数据将被放置到Apache Lucene索引中。
可以给每个索引设置索引级别,有两种类型的设置:
- static
静态索引设置只能在索引创建时设置。
- dynamic
动态索引设置可以通过更新索引设置API实时更改索引设置。
2、API
- 创建索引
语法:
PUT /<index>
样例:
PUT /my-index-000001
执行curl -X PUT "localhost:9200/my-index-000001?pretty":

创建索引时还可以指定:索引的设置(settings)、索引中字段的映射(mappings)和索引别名(aliases)。
样例:
PUT /my-index-000001
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
},
"mappings": {
"properties": {
"field1": {"type": "text"}
}
},
"aliases": {
"alias_1": {
"filter": {
"term": {"user.id": "kimchy"}
}
},
"alias_2": {}
}
}
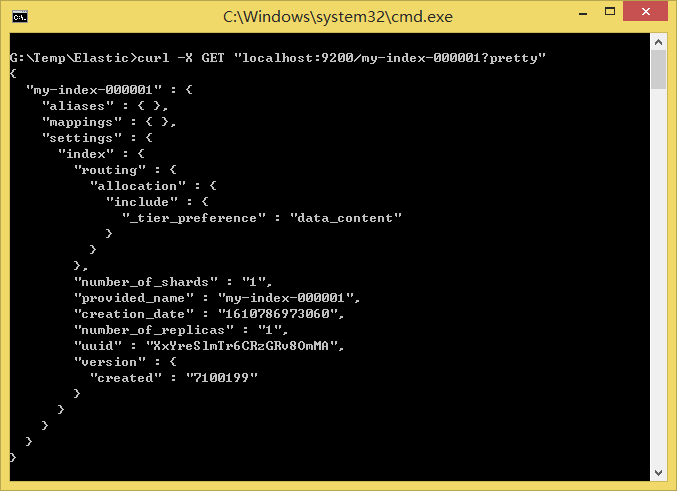
- 获取索引
GET /my-index-000001
样例:
执行curl -X GET "localhost:9200/my-index-000001?pretty":
- 获取索引设置:
GET /my-index-000001/_settings
对应的URL请求:
curl -X GET "localhost:9200/my-index-000001/_settings?pretty"
还可以获取索引字段映射和别名等。
- 获取索引统计信息
GET /my-index-000001/_stats
- 检查索引是否存在
HEAD /my-index-000001
执行curl -I "localhost:9200/my-index-000001?pretty":

- 更新索引设置
PUT /my-index-000001/_settings
{
"index" : {
"number_of_replicas" : 2
}
}
- 删除索引
DELETE /my-index-000001
curl -X DELETE "localhost:9200/my-index-000001?pretty"
- 刷新(Flush)
刷新数据流(data stream)或索引(index)是确保当前仅存储在事务日志中的任何数据也永久存储在Lucene索引中的过程。当重新启动时,Elasticsearch将事务日志中任何未刷新的操作重新放入Lucene索引,以使其恢复到重新启动前的状态。
POST /my-index-000001/_flush